2022. 1. 23. 21:30ㆍ파이썬/머신러닝
앙상블
앙상블이란 여러 모델을 이용해서 하나의 예측을 이끌어내는 방식을 말한다.
가장 단순한 앙상블 방법은 아래와 같다.
1. 주어진 데이터에 대해 예측 모델을 만들고 예측 결과를 기록한다.
2. 같은 데이터에 대해 여러 모델을 만들고 결과를 기록한다.
3. 각 레코드에 대해 예측된 결과들의 평균(또는 가중평균, 다수결 투표)를 구한다.
즉 동일한 데이터에 대해 여러 모델로 결과를 내고, 그 결과를 회귀일 경우 평균(혹은 가중평균)을 내고 분류일 경우 다수결 투표로 결과를 얻는 방식을 말한다.
앙상블의 장점은 적은 노력만으로 좋은 예측 모델을 만둘 수 있다는 점이다.
단순한 앙상블 방법 외에, 가장 많이 사용되는 배깅과 부스팅이라는 앙상블 방법이 있고, 트리 모델일 경우에 랜덤 포레스트와 부스팅 트리가 각각에 해당된다.
배깅
배깅이란 '부트스트랩 종합(boostrap aggregating)'의 줄임말이다. 배깅은 다양한 모델들을 정확히 같은 데이터에 대해 구하는 대신, 매번 부트스트랩 재표본에 대해 새로운 모델을 만든다.
부트스트랩은 복원추출을 의미한다. 예를 들면 1부터 10까지의 데이터가 있다. 만들 모델의 개수 M과 사용할 record의 개수 n개를 설정하고 재표본추출을 한다.

각기 다른 데이터에 대해 모델을 생성하는 것이 바로 배깅이다.
예제
for _ in range(10): # 데이터셋을 10번 반복복원추출, Sampling 개수와 동일range(n)
# 반복 복원추출과정
data_index = [data_index for data_index in range(train_x.shape[0])]
random_data_index = np.random.choice(data_index, train_x.shape[0]) # 복원추출을 의미
print(len(set(random_data_index))) # unique한 것을 뽑음, data의 63%가량 unique data 추출
sm_train_x = train_x.iloc[random_data_index,]
sm_train_y = train_y.iloc[random_data_index,]위는 복원 랜덤표본추출을 통해 10개의 새로운 데이터셋을 구성하는 코드이다. 위에 생성된 데이터로 모델을 각 루프마다 만들면 될 것이다.
sklearn 라이브러리에서도 지원하고 있다.
bagging_decision_tree_model1 = BaggingRegressor(base_estimator = decision_tree_model, # 의사결정나무 모형
n_estimators = 500, # 30번 샘플링
verbose = 1) # 학습 과정 표시
tree_model2 = bagging_decision_tree_model1.fit(x_train, y_train) # 학습 진행
predict2 = tree_model2.predict(x_valid) # 학습된 Bagging 의사결정나무 모형으로 평가 데이터 예측
print("RMSE: {}".format(sqrt(mean_squared_error(predict2, y_valid)))) # RMSE 결과BagginRegressor인데 base_estimator에 모델을 넣어주고 샘플링 횟수를 적어주면 된다.

위 성능은 배깅을 적용하지 않았을 때의 DecisionTreeRegressor이다.

배깅을 적용하면 RMSE값이 더 낮아진 것을 확인할 수 있다.
랜덤 포레스트
랜덤포레스트는 의사 결정 트리 모델에 배깅 방법을 적용한 모형이다. 단 랜덤 포레스트에서는 트리 모델의 알고리즘인 분할 지점을 결정할 때의 선택할 수 있는 변수가 랜덤하게 결정된 전체 변수들의 부분집합에 한정된다. 즉 분할을 할 때 변수에 대해 부트스트랩 샘플링이 추가가 되는 것이다.
데이터 셋에만 변화를 주는 것이 아니라 변수에 또한 영향을 주는 것을 예를 든다면, 자동차 데이터 셋에 아래와 같은 변수가 있다고 생각해보자.

처음 분할 지점을 결정할 때, random으로 선택하여 가격과 문의 개수, 안전 등급이 선택된다면(보통 feature의 제곱근의 수로 선택을 한다.), 이 셋 중에서 분할 변수를 선정하도록 한다. 이 과정을 트리가 만들어질 때까지 반복한다.
랜덤 포레스트는 여러 개의 의사 결정 나무를 형성하고 각 트리가 분류한 결과에서 투표를 실시하여 가장 많이 득표한 결과를 최종 분류 결과로 선택한다. 많은 수의 트리로 인해 오버피팅의 영향을 덜 받기 때문에 더 좋은 성능을 낼수도 잇다.
from sklearn.ensemble import RandomForestRegressor
classifier = RandomForestRegressor(n_estimators=500, n_jobs=-1)
classifier.fit(x_train, y_train)
predict3 = classifier.predict(x_valid)
print("RMSE: {}".format(sqrt(mean_squared_error(predict3, y_valid))))randomforest는 sklearn에서 지원하고 있다. 위코드를 통해 간단하게 이용할 수 있다

여러 머신러닝 알고리즘과 마찬가지로 랜덤 포레스트는 성능을 조절할 수 있는 여러 하이퍼파라미터가 있다. 결과에 결정적인 영향을 미치기 때문에 잘 선정을 해주어야 한다. 랜덤 포레스트에는 두 가지 가장 중요한 하이퍼파라미터들이 존재한다.
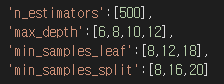
위는 각각 결정 트리의 개수, 트리의 깊이, 노드에 있어야 하는 최소 데이터 수 ,내부 노드를 분할하는 데 필요한 최소 데이터 수이다.
이 것을 일일히 수동으로 찾아보는 것에는 시간이 오래 걸린다. sklearn에서는 GridSearchCV로 자동화를 지원한다.
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer, mean_squared_error
params ={
'n_estimators':[500],
'max_depth':[6,8,10,12],
'min_samples_leaf':[8,12,18],
'min_samples_split':[8,16,20]
}
rf = RandomForestRegressor(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf, param_grid=params, scoring='neg_mean_squared_error' , cv=2, n_jobs=-1)
grid_cv.fit(train_x, train_y)
y_pred = grid_cv.predict(test_x)
predict 함수를 사용하면 가장 성능이 좋은 파라메터로 예측을 해준다.

시도해본 하이퍼 파라메터를 보고 싶다면 위와 같이 코드를 작성하면 된다.

베스트 파라메터는 위의 코드로 확인할 수 있다.
부스팅 알고리즘
앙상블 모델은 예측 모델링 쪽에서 표준 방법이 되고 있다. 부스팅은 모델들을 앙상블 형태로 만들기 위한 일반적인 기법이다. 부스팅 역시 결정 트리에 많이 사용된다. 부스팅은 훨씬 많은 부가 기능을 갖고 있는 전혀 다른 방법이다.
부스팅이란 이전 모델이 갖는 오차를 줄이는 방향으로 다음 모델을 연속적으로 생성하는 것이다. 선형회귀 모델에서 피팅이 더 개선될 수 있는지 알아보기 위해 잔차를 종종 사용했다. 이러한 개념을 발전 시켜서 부스팅이 탄생했다.
잔차가 큰 레코드에 가중치를 주어서 일련의 모델들을 생성하는 것이다.
부스팅 알고리즘에는 5가지 정도가 있다.
- AdaBoost (이전 오류에 가중치를 곱해서 결과를 평가, 높은 가중치를 가진 데이터 포인트가 존재하면 성능이 크게 떨어짐.)
- GBM(Gradient Boosting Machine) (비용함수를 경사하강법을 이용해 최적화. 과적합 이슈)
- XGBoost
- LightBoost
GBM에 가중치 업데이트에 경사하강법이 도입되었는데 과적합 이슈가 있어 개선된 버전인 XGB가 나오게 되었다.
현재는 XGB와 LightBoost가 많이 사용됨.
경사하강법은 딥러닝의 최적화 기법으로도 사용되기도 함.
예시
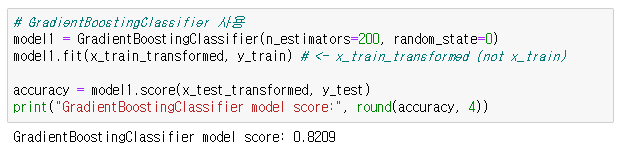
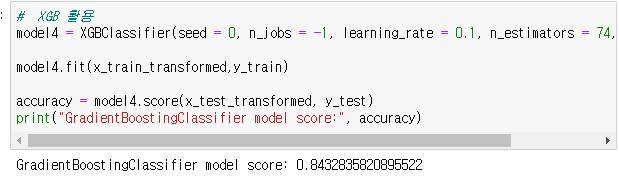
XGboost의 하이퍼 파라미터








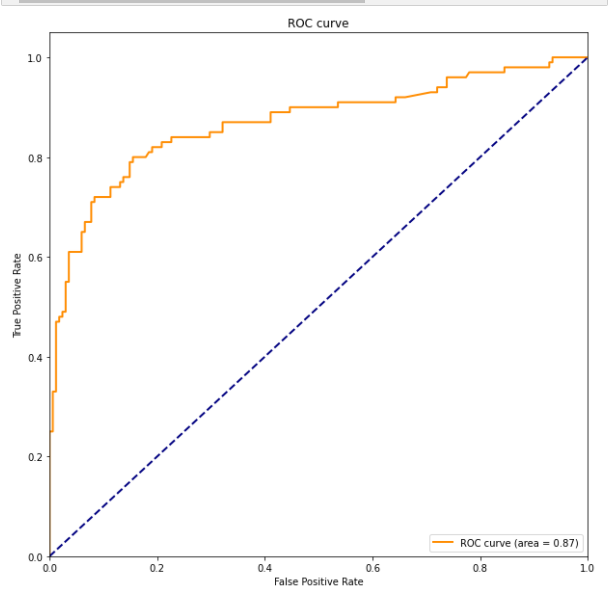
ROC 커브 : 머신러닝 모델을 평가할 때 쓰임
민감도(y, True positive rate(TPR), Recall)와 특이도(True Negative rate(TNR)) : 민감도 (예 : 실제 병에 걸린 사람이 양성 판정), 특이도 (예 : 정상인이 음성 판정)

print(recall_score(model1.predict(x_test_transformed),y_test)) # 실제로 생존한 것을, 모델이 생존했다고 예측한 수치
print(precision_score(model1.predict(x_test_transformed),y_test)) # 모델이 생존했다고 예측한 것중에 실제로 생존한 수치
print(f1_score(model1.predict(x_test_transformed),y_test))
print(recall_score(model4.predict(x_test_transformed),y_test)) # 실제로 생존한 것을, 모델이 생존했다고 예측한 수치
print(precision_score(model4.predict(x_test_transformed),y_test)) # 모델이 생존했다고 예측한 것중에 실제로 생존한 수치
print(f1_score(model4.predict(x_test_transformed),y_test))
'파이썬 > 머신러닝' 카테고리의 다른 글
| K 최근접 이웃 (KNN) 알고리즘 (0) | 2022.01.23 |
|---|---|
| K 최근접 이웃 (KNN) 알고리즘 (0) | 2022.01.23 |
| 01. 머신러닝 간단 알아보기 (0) | 2021.09.22 |