2022. 1. 23. 17:53ㆍ파이썬/머신러닝
KNN (K-nearest neighbors)
KNN은 가장 간단한 예측/분류 방법 중 하나이다.
KNN 알고리즘의 아이디어는 다음과 같다.
1. 특징(feature)들이 가장 유사한 K개의 레코드를 찾는다. (K는 임의로 정해주는 것. hyper parameter)
2. 분류 문제라면 이 레코드들 중에 다수가 속한 클래스가 무엇인지 찾은 후에 새로운 레코드를 그 클래스에 할당한다.
3. 예측 문제라면 유사한 레코드들의 평균을 찾은 후에 새로운 레코드에 대한 예측값으로 사용한다.
특징들이 어떤 척도에 존재하는지, 가까운 정도를 어떻게 측정할 것인지, K를 어떻게 설정할 것인지에 따라 예측결과가 달라진다. 또한 모든 예측변수들은 수치형이어야 한다.
예제
pandas의 sklearn 패키지에서 간단하게 KNN을 이용할 수 있다.
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors
df_loan = pd.read_csv('/content/sample_data/loan200.csv')데이터는 https://www.dropbox.com/sh/clb5aiswr7ar0ci/AABBNwTcTNey2ipoSw_kH5gra?dl=0&preview=loan200.csv
AAA - Practical Statistics
Dropbox를 통해 공유함
www.dropbox.com
이 곳에서 다운 받는다.

변수 payment_inc_ratio는 소득에 대한 대출 상환 비율이며 dti는 소득에 대한 부채 비율을 뜻한다. (모두 100을 곱한 값)
위 0번째 레코드의 대출 연체를 예측해볼 것이다.
df_loan.loc[df_loan.outcome=='paid off','outcome'] = 0
df_loan.loc[df_loan.outcome=='default','outcome'] = 1
target = df_loan.iloc[:1,1:]
train = df_loan[1:]
x = train.iloc[:,1:].values
y = train['outcome'].values
model = neighbors.KNeighborsClassifier(6)우선 예측을 할 outcome 열의 값을 0과 1을 치환해주고 기타 전처리를 해준다.
target은 우리가 예측할 값이고 train은 모델을 구성하는 데이터이다. train을 다시 예측 변수(예측을 하는 것에 필요한 데이터)와 종속 변수(예측을 할 데이터)로 나누어 준다.
y = list(map(lambda x:int(x),y))
model.fit(x,y)
target = target.values
model.predict(target)y값이 object type이기 때문에 int로 바꾸어준다. 그리고 모델을 fitting 해준 뒤 target을 예측해준다.

1 (연체 안함)이 나오는 것으로 볼 수 있다.
시각화
model = neighbors.KNeighborsClassifier(30)
model.fit(x, y)
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]) # XY 좌표계 상의 각각의 Point에 대하여 KNN model 로 class prediction을 진행
Z = Z.reshape(xx.shape) # xx.shape == (220, 280)
plt.figure(figsize=(10,5))
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cmap_bold, edgecolors='gray')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = 30)")
plt.show()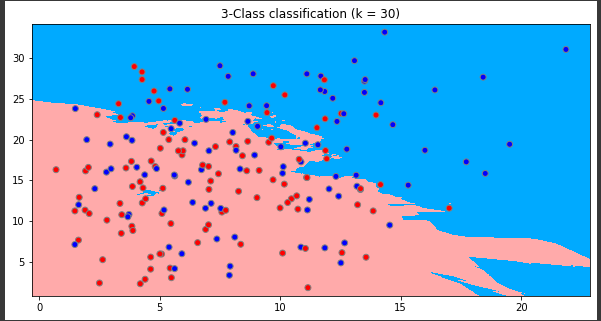
거리 지표
거리 지표는 예측하고자 하는 값을 결정할 때 중요한 값이다. 이 거리를 유사성이라고도 말한다.
유사성은 거리 지표를 통해 결정된다. 두 벡터 사이에 가장 많이 사용되는 지표는 유클리드 거리이다.

유클리드 거리는 서로의 차이에 대한 제곱합을 구한 뒤 그 값의 제곱근을 구한다.
다음으로 많이 사용되는 거리 지표는 맨하탄 거리이다.
맨하탄 거리는 서로의 차이에 절대값의 모든 합이다.


유클리드 거리는 두 점 사이의 직선 거리, 맨하탄 거리는 대각선이 아닌 한 축 방향으로만 움직일 때의 거리이다.
K 선택하기
K는 모델의 성능에 가장 중요한 영향을 미치는 값이다. K를 1로 두게 되면 가장 가까운 데이터를 찾아 예측 결과로 사용한다. 하지만 K > 1일 때 더 좋은 결과를 보인다.
일반적으로 K가 너무 작으면 오버피팅 문제가 발생하고 너무 크면 오버스무딩의 문제가 발생한다.
최적의 K 값을 찾기 위해 홀드아웃 데이터로 정확도 지표들을 활용한다.
일반적으로 손글씨 데이터 또는 음성 인식 데이터처럼 노이즈가 없고 잘 구조화된 데이터의 경우 K값이 작을 수록 잘 동작한다. 대출 데이터와 같이 노이즈가 큰 데이터는 K가 클수록 좋다.
보통 K는 1에서 20사이에 두고, 동률이 나오는 경우를 막기 위해서 홀수를 사용한다.
정확도를 측정하는 코드는 아래와 같다. (따로 홀드아웃 샘플이 존재하는 붓꽃 데이터 샘플을 가져왔다.)
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris['data'], columns=iris['feature_names'])
df['target'] = iris['target']
df.head()
df['target'].value_counts()
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(df.iloc[:, :2], df['target'], stratify=df['target'], test_size=0.2, random_state=30)
knn = neighbors.KNeighborsClassifier()
knn.fit(x_train, y_train)
prediction = knn.predict(x_valid)
(prediction == y_valid).mean()
for k in range(1, 11):
knn = neighbors.KNeighborsClassifier(n_neighbors=k, n_jobs=-1)
knn.fit(x_train, y_train)
score = knn.score(x_valid, y_valid)
print('k: %d, accuracy: %.2f' % (k, score*100))결과

'파이썬 > 머신러닝' 카테고리의 다른 글
| 앙상블 기법 : 배깅과 랜덤 포레스트, 부스팅 (0) | 2022.01.23 |
|---|---|
| K 최근접 이웃 (KNN) 알고리즘 (0) | 2022.01.23 |
| 01. 머신러닝 간단 알아보기 (0) | 2021.09.22 |