2021. 9. 5. 21:41ㆍ파이썬/데이터 스크래핑
자 이제 함 다시 가보자. 우리 저번 시간엔 네이버 뉴스 검색창에서 링크만을 가져왔다. 이제 그 링크에 접속해보즈아~
우선 한개의 뉴스 기사만을 본문으로 가져오는 코드를 짜보자. 자동으로 하나씩 방문하는 코드는 나중에 짜보겠다.

엥 ;; 왜 오류가 뜨지;; 아하 로봇이라고 생각해서 커넥션을 끊었나보다. 아무래도 뉴스 같은 정보를 그냥 쉽게 스크래핑을
해가면 골치 아프니까 그런가보다. 그럴 땐 header라는 것을 같이 입력해주면 된다. 헤더의 위치는

요거다. 개발자도구 컨트롤 + 쉬프트 + i 누르고 네트워크 들어간뒤 name 탭에 가장 상단의 파일을 누른다.
그리고 user-agent에 있는 정보를 같이 입력해주면 된다.
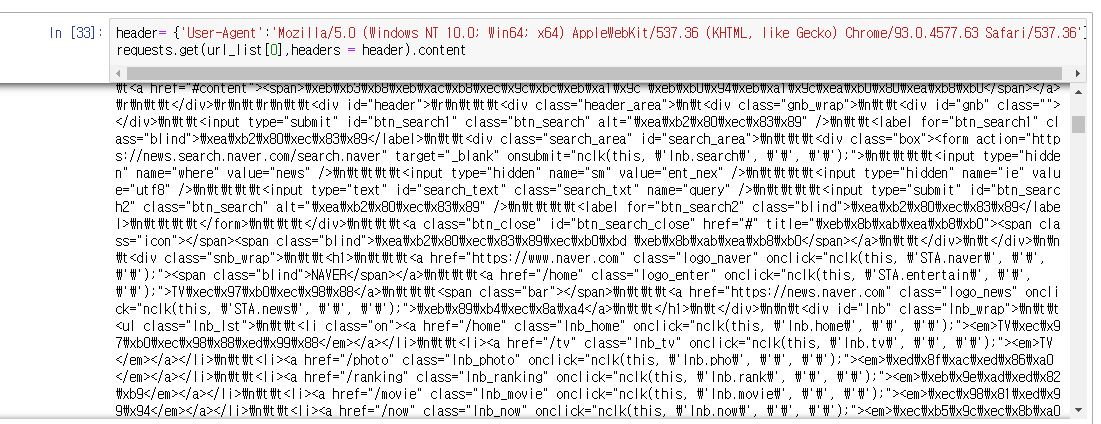
계속 오류가 떠서 확인해보니 헤더 안에 딕셔너리 형식으로 'User-Agent' : '쏼라쏼라' 이렇게 써주어야 한다. 꼭!!
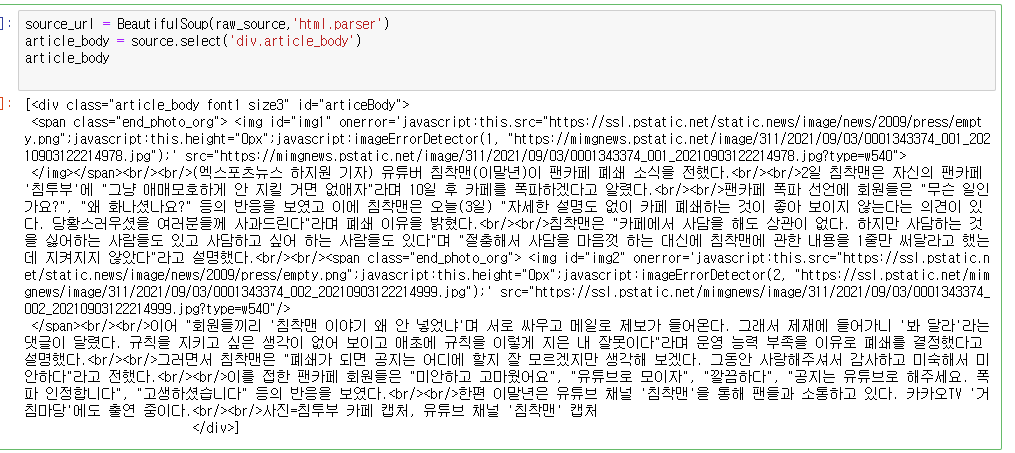
자 이렇게 똑같이 가져왔다. 근데 여기서 문자열만 쏘옥 빼오려면 어떻게 해야할까 그전에 리스트를 문자열로 바꾸어서 가공하기 편하게 만들자.

str타입 함수 중에 join이라는 함수가 있는데 이 join이라는 함수는 배열(문자열도 배열이다)의 모든 원소들을 결합한다. 하지만 배열의 모든 원소가 문자열이여야만 하기때문에, map을 써주면 좋다. map 함수는 지정한 타입을 모든 배열의 원소들에 대하여 실행한다. 그렇게 모든 원소가 str이 되면 join을 쉽게 실행할 수 있게 된다.

지 이런식으로 정규표현식을 이용해 한글만 쉽게 가져올 수 있다.하하하 어짜피 데이터분석용이니까 걍 이렇게 가져와도 됨..ㅎ=ㅇ 아님

이런식으로 거슬리는 건 replace함수를 통해 제거해 줄 수 있다.

마찬가지로 기사 타이틀도 이렇게 넣어주고

이메일과 이름을 정규표현식으로 분리해주고

신문사까지 추출해주면

이런 식으로 완성이 된다!!
그 다음은 우리가 가지고 있는 url 리스트를 개별적으로 접근하여 가져오는 방법에 대해 알아보도록 하겠다.
'파이썬 > 데이터 스크래핑' 카테고리의 다른 글
| HTML 소스에서 태그와 개행문자 날리기 (0) | 2022.02.03 |
|---|---|
| 03. 침착맨의 기사를 여러 페이지, 다양한 정렬로 스크래핑 해오자. (0) | 2021.09.07 |
| 02. 스크래핑한 내용을 판다스 DataFrame에 저장하기 (01 복습) (0) | 2021.09.06 |
| 0. 웹에서 원하는 정보를 긁어오자. (0) | 2021.09.04 |