2021. 9. 4. 00:56ㆍ파이썬/데이터 스크래핑
웹 스크래핑
자 일단 웹스크래핑은 정보를 모으는 일이다. 내가 원하는 웹사이트에서
원하는 정보를 얻을 수 있다는 점은 누구나 도전해볼만 하다. 알제?
그래 일단 코린이인 내 수준에서 웹에서 정보를 가져오는 행위를 해보자.
일단 생각을 좀 정리하고 음.. 일단 URL을 분석을 해야할 것 같다.
https://search.naver.com/search.naversm=tab_hty.top&where=news&query=%EC%B9%A8%EC%B0%A9%EB%A7%A8&oquery=%EC%B9%A8%EC%B0%A9%EB%A7%A8&tqi=hg4iFlprvxZss4fv3p0ssssstwo-108461
일단 가져왔다. 이상하게 URL을 가져오면 이렇게 길어지더라. 왜 그런건지 설명점.. 암튼 방법이 있다.
https 앞에 마우스 커서를 둔다. 그리고 스페이스바를 누르고 한칸 띄우고 복사를 하면
이런식으로 나온다. 그냥 뭔가 필요 없을 것 같은 걸 지워보자
https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query=침착맨
자 이렇게 해도 들어가진당. 그리고
https://search.naver.com/search.naver?where=news&query=침착맨
자 가운데 있는 sm어쩌구를 없애도 잘 된다. 이 것을 기준으로 설명을 하자면


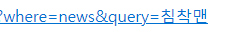
자 URL을 구성하는 부분을 쓸데 없이 길게 보았다. 음 근데 왜 분석한거지?

검색을 하면 이런 화면이 나온다. 저 중에서 네이버가 특별히 엄선한 뉴스로 들어가서 기사의 타이틀, 그리고 링크 속 내용을 내 컴퓨터에 저장하는 코드를 짜보겠다.

자 이런 식으로 만들어 준다. 내가 접근하려는 웹사이트를 변수로 만든거다. 자 이제 URL의 정보를 긁어오려면
라이브러리를 사용해야겠죠?
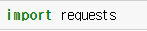
requests 형님이다. 우리대신 URL을 방문해서 정보를 가져오는 미친 도둑놈이다. 자 직관적으로 .get(URL) 함수를 사용하면 된다.
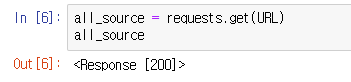


자 저 리스폰스 200은 잘 접속을 했다는 뜻이다. 저 받아온 정보는 .text를 사용하면서 확인할 수 있다. 하지만 이 상태에선 사용하기 힘들다. 참고로 주피터 노트북(찐 노트북 아님.)이 아니면 print(all_source) 이런 식으로 써주면 될거다. 그게 불편하면 주피터 노트북 써라, ^^호호 그리고 get클래스 뒤에 .content를 쓰면 불러오는 정보량을 어느정도 줄여줄 수 있다. 이제 저 데이터를 html으로 가공해야만 우리가 뭘 하든 말든 한다.

저 위에 사용하는 bs4라는 라이브러리를 가져온다. 그리고 우리가 사용할 건 Beauti 어쩌구 기능만 사용할 거니까 저것만 가져온다. 오우 쒯

이거 하면서 오류가 나서 위에 request.get(URL).content로 고쳐주었더니 되었다;; ㅋㅋㅋ 암튼 이걸로 하자 알겄노
자 이제 본격적으로 들어간다.
크롬 기준으로 한다. 컨트롤 + 쉬프트 + i 로 개발자 도구를 켠다.

자 좌상단에 있는 박스안의 화살표를 눌른다.

그리고 저 내가 누른 저 보라색 타이틀을 누르면

그러면 저 개발자도구에서 소스코드를 볼 수 있다. 걍 어려워할 거 없다.보면 앞에 태그와 id나 class를 찾으면 된다.
이 경우 태그는 'a'와 클래스 'news_tit'이 딱 보인다. 그럼 select() 함수로 이와 같은 구조를 가진 링크를 모조리 찾아올 수 있다. 한마디로 이놈 네이버 뉴스들이 리스트에 규칙성 있게 정렬을 해놓았기 때문에 가능한 일이다.

이렇게 말이다. 아주 예쁘게 타이틀과 링크를 리스트 형태로 다 가져왔다. 리스트로 가져오면 for문을 돌리면서 원하는 정보를 챙겨올 수 있다. 여기서 타이틀과 링크를 어떻게 가져오면 좋을까.

일단 이 news_list라는 변수로 저장해주고.!

타이틀을 담을 박스! 리스트를 하나 만들어 준다! 이 리스트에 타이틀을 담을거임!!!ㅋㅋ

그리고 우리가 리스트 형태로 가져온 news_list를 돌려준다. 알져? 그럼 리스트의 크기만큼 안에 있는 내용을 하나씩 차례대로 배출한다. 그리고 빈 박스인 news_titles에 그 내용을 하나씩 추가해준다. list는 append 함수! 매개 변수로 news_list의 하나 하나의 내용인 news_source의 text값만을 얻기 위해 저렇게 써준다. 그러면

이렇게 news_list를 얻을 수 있다. 사실 다른 방법도 있다. 그리고 이건 링크와 타이틀을 한꺼번에 얻을 수 있는 방법이다.

우리가 포문을 돌렸던 news_source, 즉 news_list의 차례대로의 원소들은 뒤에 attrs 함수를 써주면 저런 딕셔너리 타입을 얻을 수 있다. 딕셔너리는 key값만 입력하면 값을 얻을 수 있재~

이렇게 하면 한꺼번에 얻을 수 잇재! 함 볼까??

자 잘 이렇게 저장된걸 볼 수 있다.
이렇게 타이틀이랑 링크를 얻었다. 근데 한가지 간과한 점이 있다 저 링크를 들어가서 본문을 스크랩을 하려면 각 웹사이트에 대응하는 스크래퍼를 만들어야 하는 좆 같은 상황이 발생한다. 자 여기까지는 연습인 샘 치고 다시 웹사이트 화면으로 돌아가보자;;

좌상단의 저 네모안의 커서모양 클릭하고

이 네이버뉴스를 클릭해준다.
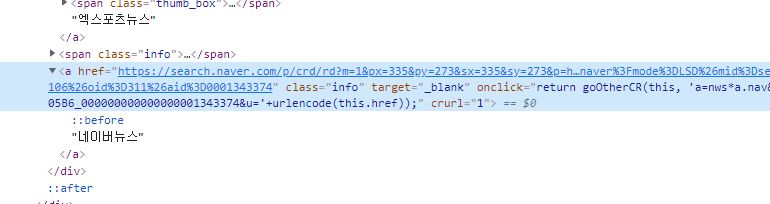
그럼 https//search.naver로 시작하는 URL이다. 그렇다! 타이틀을 누르고 들어가면 있는 URL과 저 네이버뉴스를 눌러 들어가면 있는 URL은 다르다! 직접 눌러서 비교해보삼!!!
그럼 이렇게 뜬다.. 그럼 다시 만들어보자..;; 태그 a와 클래스 info는 뭐다?

select 함수로 찾으면 그만~ 개 쉽쥬..
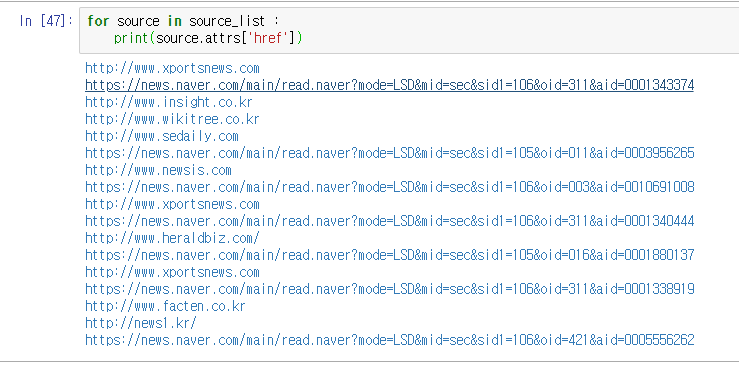
그리고 위에 배웠던 내용을 다시 적용해보면 드디어 네이버 뉴스가 나오기 시작한다~ 앙 개꿀띠~
자 그럼 저 네이버 링크만 거르게 만드는 방법이 있다. 바로 .startwith('문자열~')을 쓰면 문자열로 시작하지 않는다면 false를 배출한다~
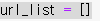
url을 담을 통을 만들고~
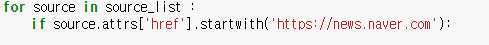
필터링 성격의 if를 넣는다. .startwith('문자열~')을 쓰면 문자열로 시작하지 않는다면 false를 배출해서 안에 코드 실행 안할꺼야 라는 뜻이다.

이렇게 리스트에 추가한다는 코드를 안에 작성해주면 완료! 이제 실행해주면 보시다시피 리스트를 돌면서 조건에 맞는 URL만 우리의 박스에 저장할 것이다.
다음편에 계속..
'파이썬 > 데이터 스크래핑' 카테고리의 다른 글
| HTML 소스에서 태그와 개행문자 날리기 (0) | 2022.02.03 |
|---|---|
| 03. 침착맨의 기사를 여러 페이지, 다양한 정렬로 스크래핑 해오자. (0) | 2021.09.07 |
| 02. 스크래핑한 내용을 판다스 DataFrame에 저장하기 (01 복습) (0) | 2021.09.06 |
| 1. 뉴스에 들어가서 여러가지 스크래핑 해오기. (0) | 2021.09.05 |