2021. 9. 9. 00:32ㆍ파이썬/데이터 분석
0. DataFrame 구경
간단하게 DataFrame에 대해 알아보겠다~
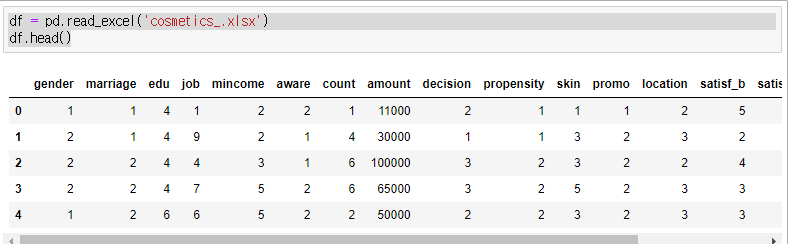
뭐 어떤 파일이든 불러와준다. read_파일 확장자로 많은 정형데이터를 가져올 수 있다!
df.head() 는 기본적으로 DataFrame의 앞 5행을 가져와준다. 괄호 안에 숫자를 넣으면 그 숫자만큼 행이 출력 된다.
우선 열을 접근하는 것을 기준으로 생각해야 한다. 왜냐하면 DataFrame자체가 dict를 출력하듯이 대괄호에 key값을 넣으면 열을 출력해준다. 이건 많은 연습으로 익숙해져야 한다. 사실 별거 없음? 그냥 안 익숙해서 그럼.

이런식으로 구매 비용을 출력해주는 것이다. 참고로 영어에다가 띄어쓰기가 없다면 df.amount로 출력이 가능하다.
그럼 행은 어떻게 출력할까?

행에 접근하려면 .loc[] 함수의 대괄호에 key값을 입력해주면 된다. key값이 아닌 순서로 접근하려면 .iloc를 사용한다.
또한 우리가 셀에 접근 하려면 어떻게 할까?
자 이렇게 5가지 방법이 있다. 하나씩 차례대로 설명하자면
1. 열에 접근한뒤 행에 접근에서 셀에 접근
2. 행에 접근해서 열에 접근한뒤 셀에 접근
3. 행과 열을 지정
4. 행과 열을 지정 (셀에 접근할 때는 이게 베스트다. 위의 loc는 굉장히 연산이 많이 일어나는 환경에서 오류발생가능)
5. 0번째 행의 7번째 열에 접근한다. 즉 이것도 행과 열을 지정
쓰고나니까 별로 안 중요한 것 같다.
그리고 우리가 만일 고객의 총 구매액 열을 추가 하고 싶다 그러면 바로 연산과 동시에 추가가 가능하다.
총 구매액 : 평균 1회 구매 비용 * 구매 횟수
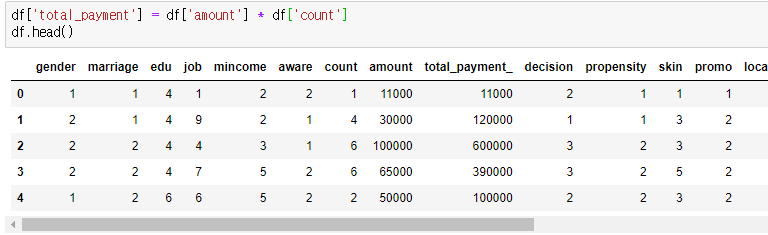
이런 식으로 새로운 열을 추가하면서 값까지 한번에 넣어줄 수 있다. 그래서 그럼 열을 추가하는 다른 방식도 알아보자
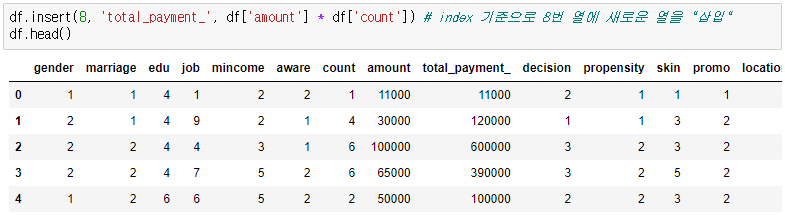
insert의 장점은 원하는 위치에 넣을 수 있다는 것이다! 그 외의 장점은 잘 모르겠다. 하암
그리고 신기한게 df의 대괄호 안에 조건식을 넣어주면 각각의 해당 열의 True, False로 반환해준다.
그걸 다시 df의 대괄호 안에 넣어주면 True에 해당되는 열만 return된다.

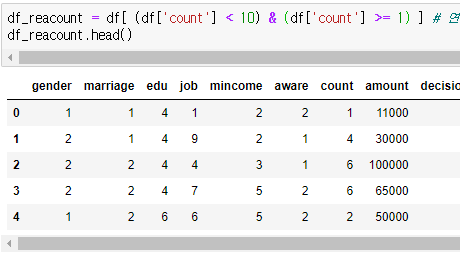
이렇게 활용이 가능하다.
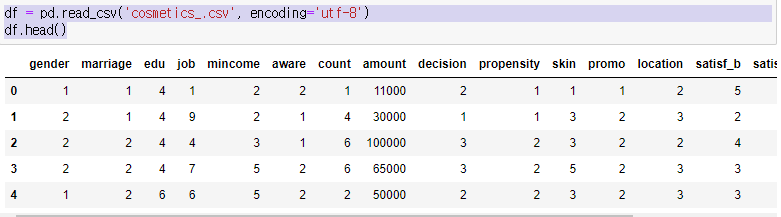
자 이 파일은 한 화장품 회사의 소비자 분석에 관한 통계이다. 아마 실제 data는 아니고 임의로 작성한 데이터가 아닌가 싶다.
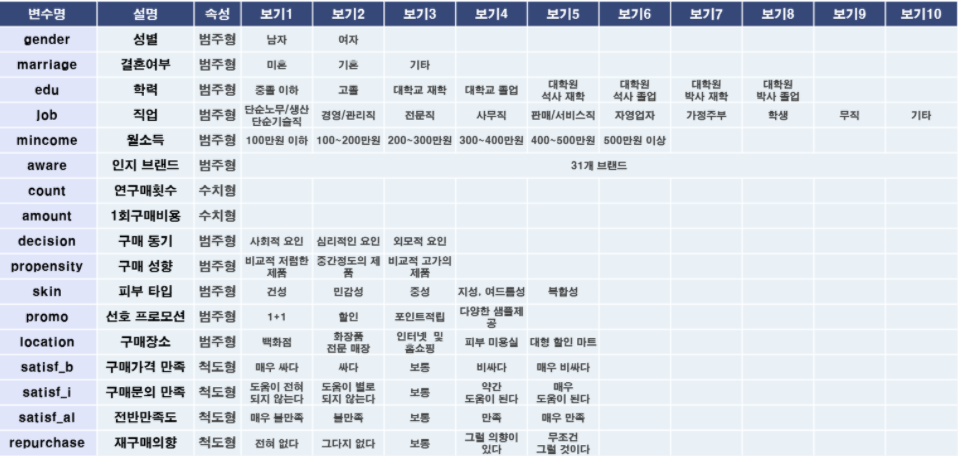
이렇게 각 변수에 대한 정보는 위 표에 나와 있다.
1. 빈도분석
우선 고객 중에 어떤 성별이 많은가? 기혼이 많은가? 미혼이 많은가?에 대한 파악을 하도록 하겠다.

자 이건 replace 함수이다. 이건 일반적인 수치, 예를 들어서 예산 , 지출, 수량 같은 것에 사용하는 건 아니고
무언가를 지칭하는 의미일 때 , 예를 들어 위와 같은 '남성' , '여성' 이나 종류 같은 독립적인 값일 때 사용할 수 있다.
(내 뇌피셜)

column의 값에 대한 빈도수를 알고 싶다면 이러한 함수를 사용하면 된다.

그 뒤에 plot() 함수를 사용하주면 빈도에 관한 그래프를 보여준다. pie를 사용하면 빈도를 쉽게 파악할 수 있다.

plot 함수에 있는 kind라는 매개변수에 bar를 사용해서 다른 형태의 그래프도 볼 수 있다.

모든 column의 최댓값을 보여주는 함수!
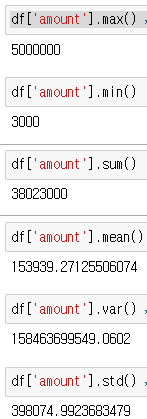
이런 식으로 해당 column에 다양한 값을 출력할 수 있다.
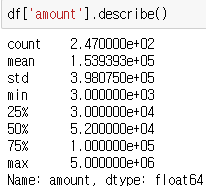
위 모든 값은 describe()에서 확인할 수 있다.

이렇게 하면 각 column의 이름, 개수, 결측치의 수, type을 확인 할수 있다.

이런 식으로 최빈값(자주 출연한 값)도 얻을 수 있다. ( 최빈값 : 2)
왜도와 첨도
왜도와 첨도는 정규 분포에서 어느 정도 벗어나 있는 지를 살표보기 위한 지표로 사용되요.
우선 왜도에 관해 간단하게 알아보도록 해요.

hist()를 사용하면 히스토그램(도수 분포도 그래프)을 얻을 수 있습니다. 이를 통해 시각적으로 왜도(치우쳐진 정도)를 알 수 있어요 0에 가까울수록 정규분포라고 가정할 수 있습니다.
긴 꼬리가 이 그래프처럼 오른쪽에 있으면 양의 왜도이구, 반대편을 바라보면 음의 왜도라고 합니다.
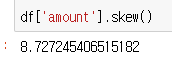
skew()를 사용하면 첨도의 수치를 얻을 수 있습니다. 첨도란 뾰족한 정도를 나타내며 분산도가 크다면 낮고 완만한 형태이고, 분산도가 적다면 뾰족하고 높은 형태로 나타납니다. 1에 가까울 수록 정규분포에 가까우며, 이 column은 굉장히 뾰족할 것 같죠? 위의 히스토그램을 보시면 됩니다.ㅎㅎ
오늘 여기까지 ㅠㅠ
'파이썬 > 데이터 분석' 카테고리의 다른 글
| 데이터 분석 기초 : 탐색적 데이터 분석 (EDA, exploratory data analysis)에 대해서 읽어 보자 (0) | 2021.12.23 |
|---|---|
| facebook prophet으로 비트코인 가격 예측해보기 (1) | 2021.12.06 |
| Pandas 시계열 데이터에 빠진 날짜 확인, 날짜 채우기 (0) | 2021.12.04 |
| 1. 넘파이와 판다스 칸탄 정리 (간단 정리) (0) | 2021.09.08 |
| 0. import pandas를 해보자. (0) | 2021.09.02 |