2022. 10. 8. 17:53ㆍ카테고리 없음
inference
모델을 쓰는 것
앱이 구동되는 공간 -> 런타임 (운영체제 의존) - > 운영체제 (하드웨어 의존) -> 하드웨어
모델을 돌리고 싶은 어플리케이션에 타겟 어플리케이션에 해당하는 인퍼런스 엔진을 찾으면 됨.
왜 오닉스 런타임이냐.
제일 넓은 커버리지를 가지고 있음. 수정이 거의 없이 다양한 플랫폼에서 가능
(파이썬과 cpp를 가장 많이 씀.)
cpp를 공부 해야 함. (서비스할 때 필요)
python 3.8 환경
pip install tensorflow
pip install onnxruntime-gpu
pip install pillow
pip install fastapi
uvicorn
python-multipart
오닉스 런타임 애플리케이션 구동 중에 라이브러리를 불러올 수 있음.
gpu를 사용한다면 코드를 실행할 때 가져와서 불러옴
오닉스 파일로 만들어서 의존성 하나씩 해결
모바일에도 관심이 있다면
ncnn
코드와 개발환경을 묶어서 도커로 만듬.
도커 이미지로 만든 뒤 가상환경에서 그것을 실행한다.
도커 이미지를 만들 때 변경된 것만 기록이 된다. (레이어 공유)
모델 레지스트리에 담아서 모델을 가져오는 방식. (모델이 커질 때)
큐버네티스는 팟이란 개념이 있고 그 위에 도커 이미지를 굴린다.
도커 이미지 확인

도커 단축키

도커 컨테이너 삭제

도커파일 실행
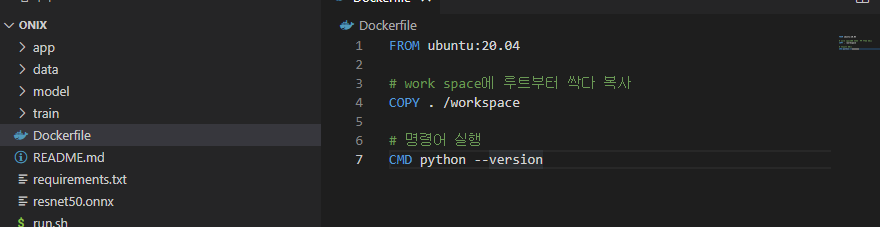
# syntax=docker/dockerfile:1
FROM ubuntu:20.04
# work space에 루트부터 싹다 복사
COPY . /workspace
# 명령어 실행
CMD python --version
도커 빌드하기 (이름:버젼)

해당 리눅스 환경 접속
docker run -it --rm test:v1 /bin/bashGitHub - tiangolo/uvicorn-gunicorn-fastapi-docker: Docker image with Uvicorn managed by Gunicorn for high-performance FastAPI we
Docker image with Uvicorn managed by Gunicorn for high-performance FastAPI web applications in Python 3.6 and above with performance auto-tuning. Optionally with Alpine Linux. - GitHub - tiangolo/u...
github.com
딥러닝 서버 환경 만들기

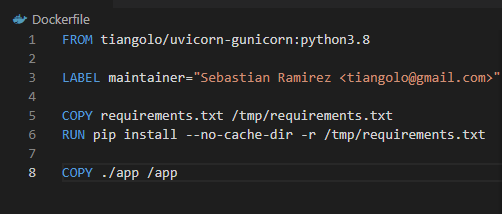
아까 도커파일에 덮어씌우기
docker build -t myserver:v1 .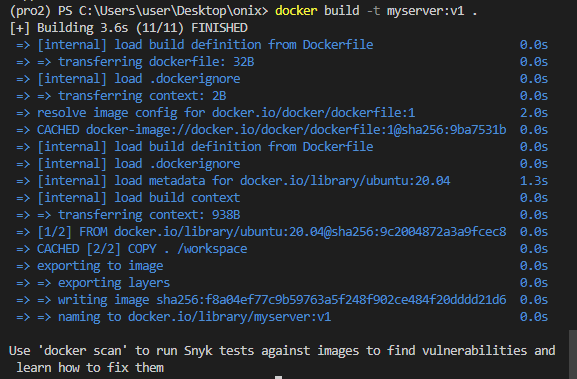
requirements.txt에
서버 실행

모델 복사 없이 빌드하기

모델이 빠져 100M 줄어듬

도커 이미지 압축하기

압축 파일 생성

도커끼리 연결(오케스트리에이션)을 위한 composer 생성 (모델이 무거울 경우, model load pattern)

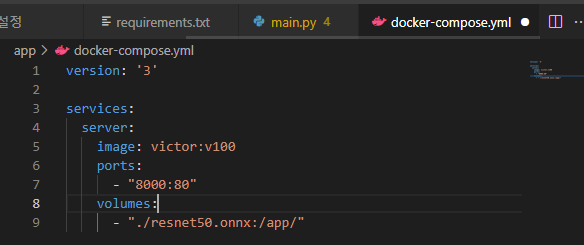
도커 컴포즈업 실행

실행시키고 돌아오기

docker-compose down

쟝고와 플라스크는 wsgi가 붙음.
gunicorn으로 병렬처리 가능 하게 됨.
fastapi는 asgi로 동시성이 가능 gpu랑 통신으로 동시에 가능. gunicorn 붙여서 병렬 처리 가능.
무조건 도커를 사용해야함.
NVIDIA 도커 (ngc docker)